报警
 报警由告警和响应两部分组成。告警让人知道什么时候问题存在,并有助于预测可能发展的问题。响应用于自动化关联告警事件和告警推送方式。
报警系统由以下三个部分组成:
报警由告警和响应两部分组成。告警让人知道什么时候问题存在,并有助于预测可能发展的问题。响应用于自动化关联告警事件和告警推送方式。
报警系统由以下三个部分组成:
Use Case
应用程序通常都会经历一些问题,如“业务交易响应时间远高于正常时间”或“内存使用率太高”等。我们需要在 报警规则 中定义怎样才是“远高于”或“太高”。也可以针对受限的环境,自定义精确的自动化报警和响应。这样就能微调系统,确保正确的警报发给合适的人。
下面我们就举几个常见的配置例子。
应用报警规则到一个节点
当应用的节点存在慢的情况,可能并不需要对每个节点存在的问题都进行报警。但是当某个关键的节点发生问题的时候,我们需要立即发出报警通知并进行处理。您可以定义适用于特定层或节点的报警规则。如果违反了这些规则,系统就知道到底哪个对象遇到问题,因此也知道需要提醒谁。下面的例子,就是只影响了一个服务器节点。
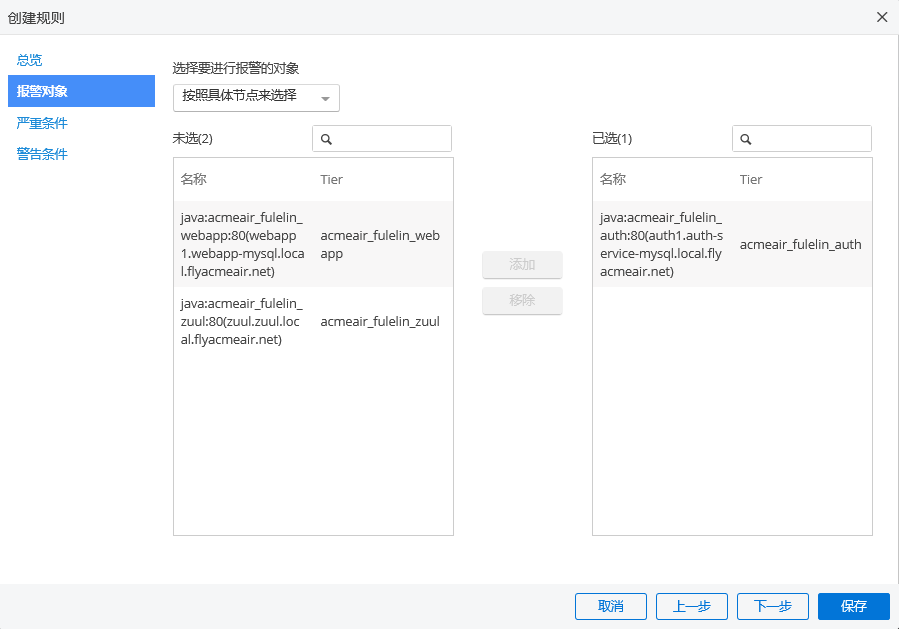
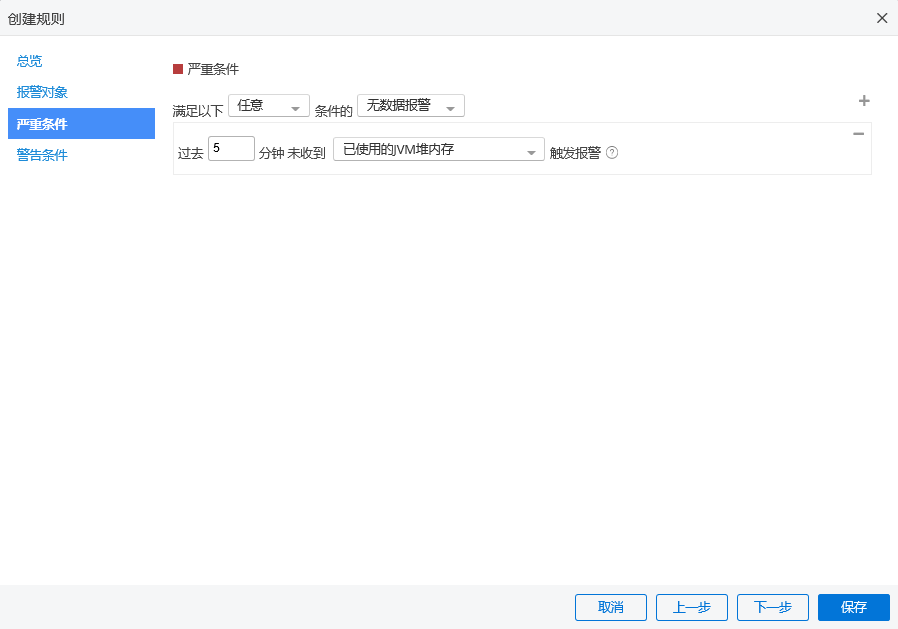
无数据报警
创建一个 节点 类型的报警规则,将条件配置为 无数据报警。这样在服务器宕机的情况下,我们就可以收到相应的报警通知并进行及时的问题处理。
注:下面图中的例子,使用了 已使用的JVM堆内存 这个指标,实际引用中,这些指标
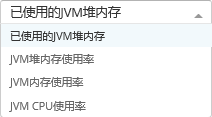
都是可以达到宕机报警的效果。
名词解释
- JVM堆内存
JVM堆内存 = young+Turned+ Perm - JVM内存
JVM内存 = 堆内存 + 非堆内存
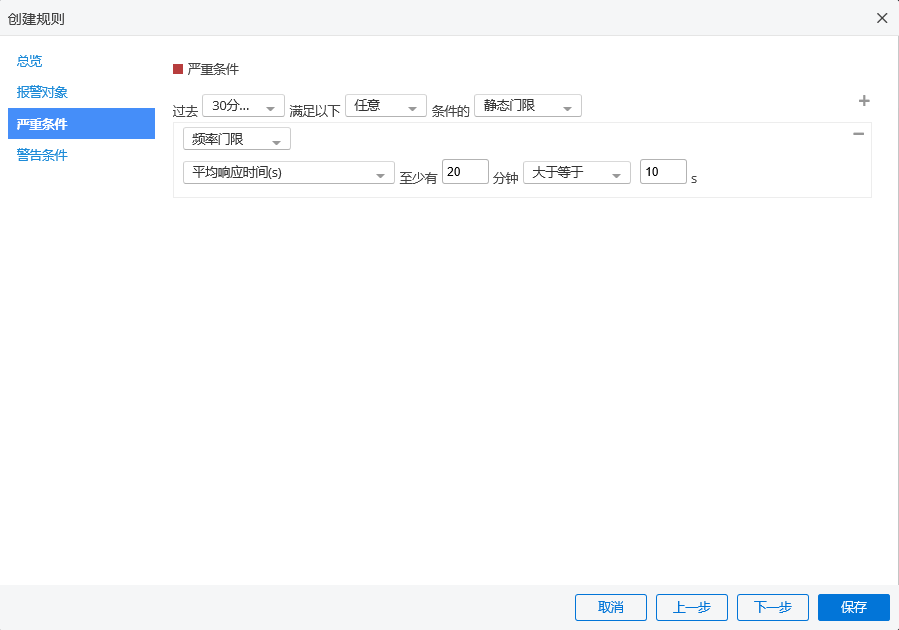
频率门限报警
应用中web事务的平均响应时间偶尔大于平均值,这样的情况是不需要报警的。但是如果这种情况频繁的出现,我们就需要进行报警并对问题进行处理。对于这种情况,我们可以通过如下的配置来达到报警的目的。
报警风暴处理
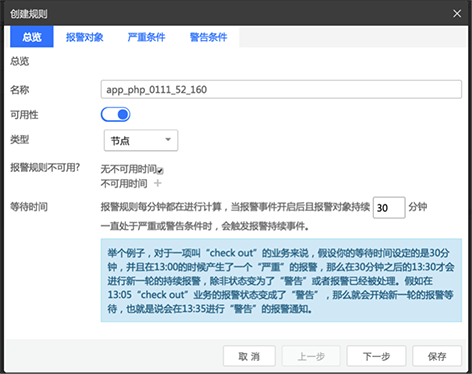
应用的健康状态时刻的在进行动态的变化,这样也就导致了报警事件的不断产生,问题邮件的不断推送。但是往往我们是不需要这样频繁的邮件发送的,这时候我们应该怎么做来减少邮件的发送频率呢?等待时间 很好的为我们解决了报警风暴的问题,我们可以通过配置 等待时间来决定邮件发送的频率。
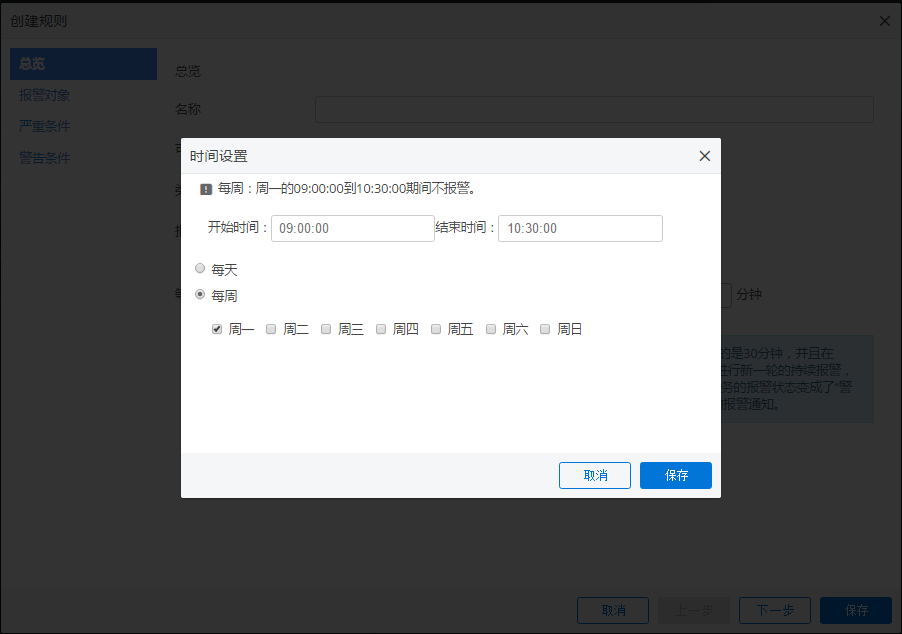
 不可用时间
不可用时间
在一般的情况下,当应用发生问题时我们需要收到报警通知并进行处理。但是再一些特殊的时间端内,问题的出现是正常的情况例如正常的系统维护导致的宕机等情况,这种情况下是不需要进行报警的。您可以通过 不可用时间 的配置来决定创建的报警规则的不可用。
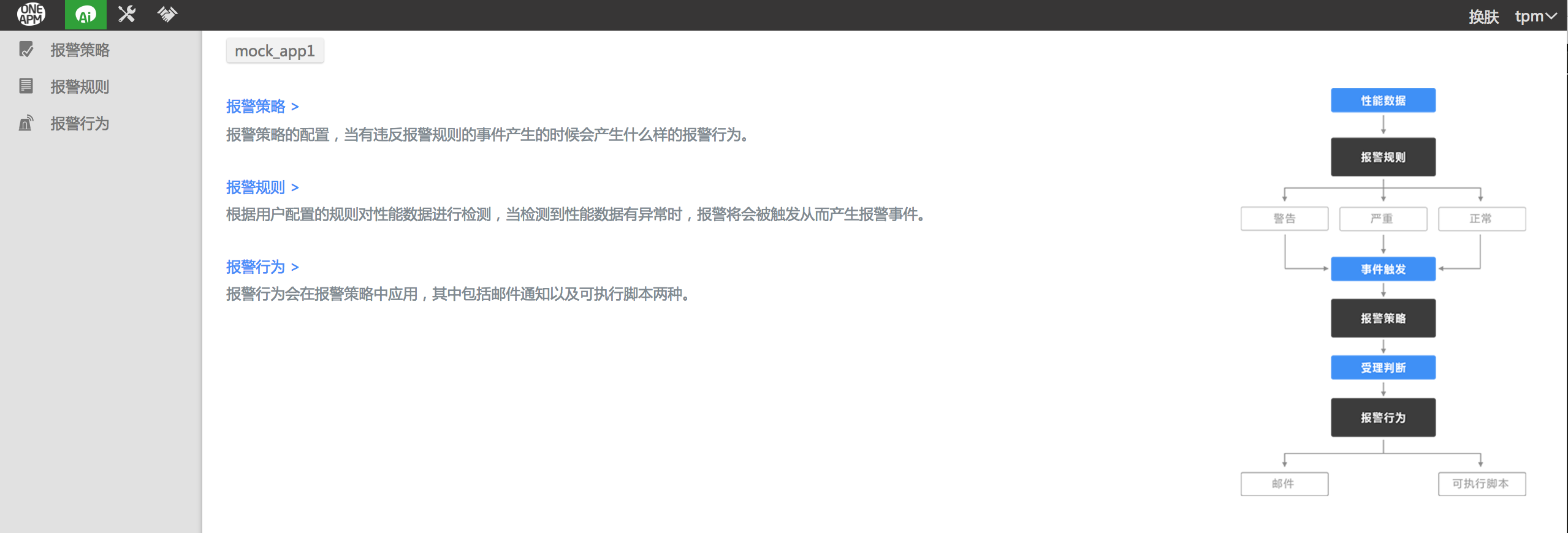
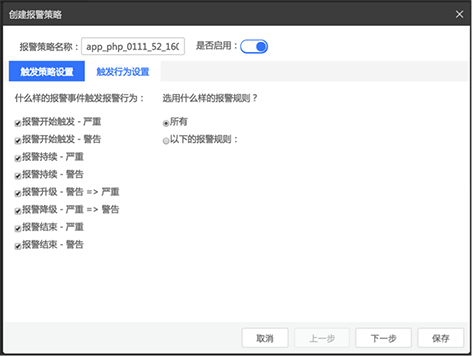
报警-报警策略
报警策略:关联报警规则与报警行为
如图:
报警-报警规则
报警规则:为应用程序定义关键性能指标阈值,根据设置的阈值生成报警事件。
如图:
 * 报警规则基于相关指标,通过定义性能等级而确立一个实体的健康状况;例如,平均响应时间(针对web事务)或CPU利用率(针对节点)过高。
* 报警规则基于相关指标,通过定义性能等级而确立一个实体的健康状况;例如,平均响应时间(针对web事务)或CPU利用率(针对节点)过高。
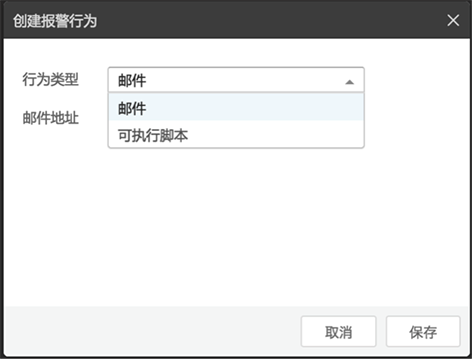
报警-报警行为
报警行为:定义推送规则。
如图: