如何使用 Ai 发现和诊断由于数据库调用产生的性能问题
引言
我们在不少项目中都会和客户的开发者或架构师一起尝试使用 OneAPM 一起分析和优化 Java 应用程序的性能问题,发现大部分的性能问题,往往并不是因为在某一个具体方法上缓慢的一两毫秒,更多的是因为糟糕的架构设计,不合适的框架配置,错误的数据库访问模式,乱打日志以及内存过度消耗导致的 GC 异常。下面我将重点介绍如何使用 Ai 发现和诊断由于数据库调用产生的性能问题。
一.常见的数据库问题大概有以下几种可能:
- 一次请求 SQL 大量执行:
- N+1 查询问题(N+1 Query):多次(30次或者更多)执行相同 SQL。
- 过多的 SQL 执行(Excessive SQLs):执行大量(大于 500)不同的 SQL 语句
- 单一 SQL 执行缓慢:
- 单一 SQL 执行缓慢(Slow Single SQL):某个单一的 SQL 语句执行时间占据了请求的响应时间的 80% 以上。
- 数据库负载较大:
- 数据库繁忙(Database Heavy):数据库执行的总体时间占据总体响应时间的 80% 以上
- 数据库服务服务器超负荷(Overloaded Database Server):来自各个应用的请求过多,造成了数据库服务器超负荷
- 数据库连接池相关问题:
- 连接池资源用尽(Pool Exhaustion):由于连接获取时间过长所导致(getConnection 的时间超过了 executeStatement) *低效的连接池访问(Inefficient Pool Access):对连接池的访问次数过多(对 getConnection 的调用超过了 executeStatement 调用次数的 50%)
我遇到过的用户案例分析:
- 问题类型:一次请求 SQL 大量执行(现象)–数据库繁忙(现象)-N+1 Query (原因)
问题发现:
由总览分析发现,用户主要耗时集中在数据库:
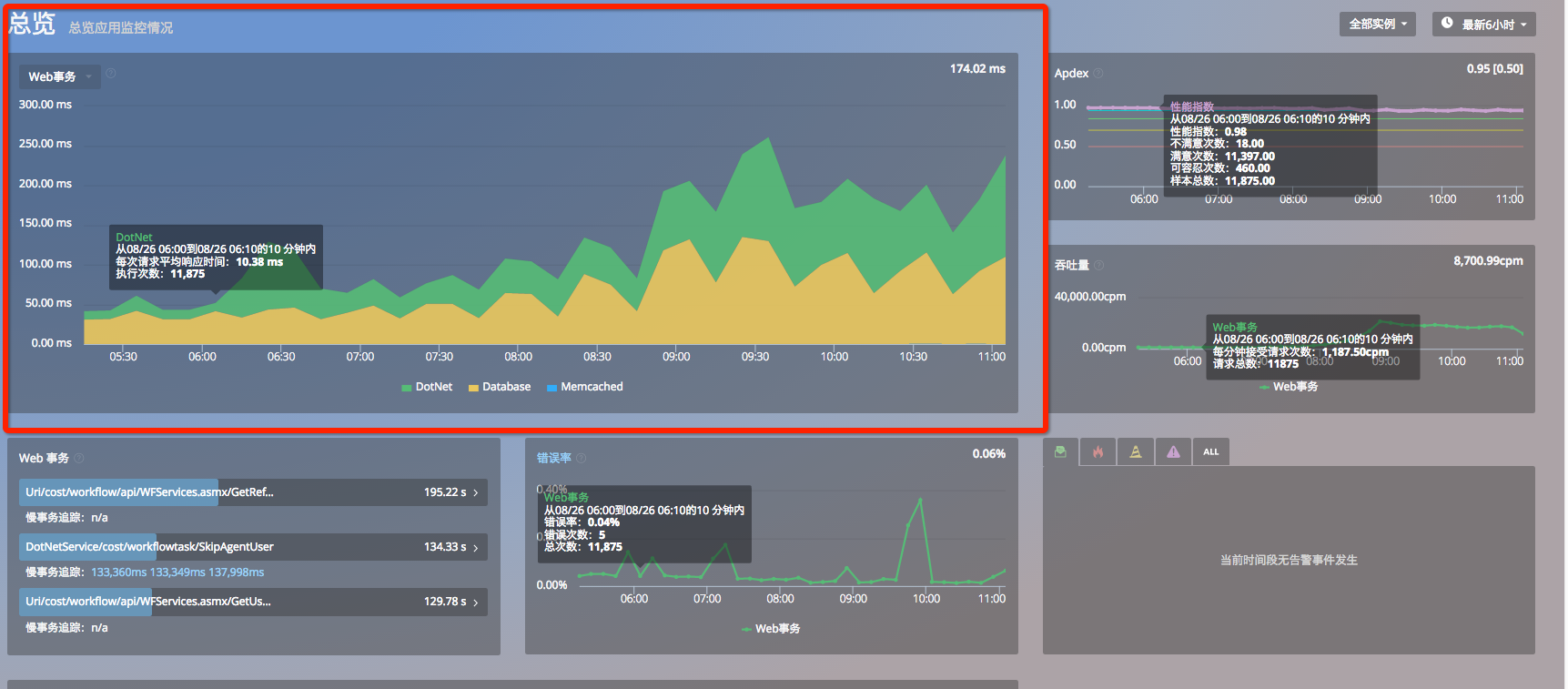 在现场分析用户最缓慢的几个 Web 事务,观察他们这几个 Web 事务对应的 breakdown,统计发现一次请求平均调用数据库的次数多达 1000 次占据了请求的响应时间占比到 90% 以上,其中最慢的请求调用数据库达上万次。
在现场分析用户最缓慢的几个 Web 事务,观察他们这几个 Web 事务对应的 breakdown,统计发现一次请求平均调用数据库的次数多达 1000 次占据了请求的响应时间占比到 90% 以上,其中最慢的请求调用数据库达上万次。
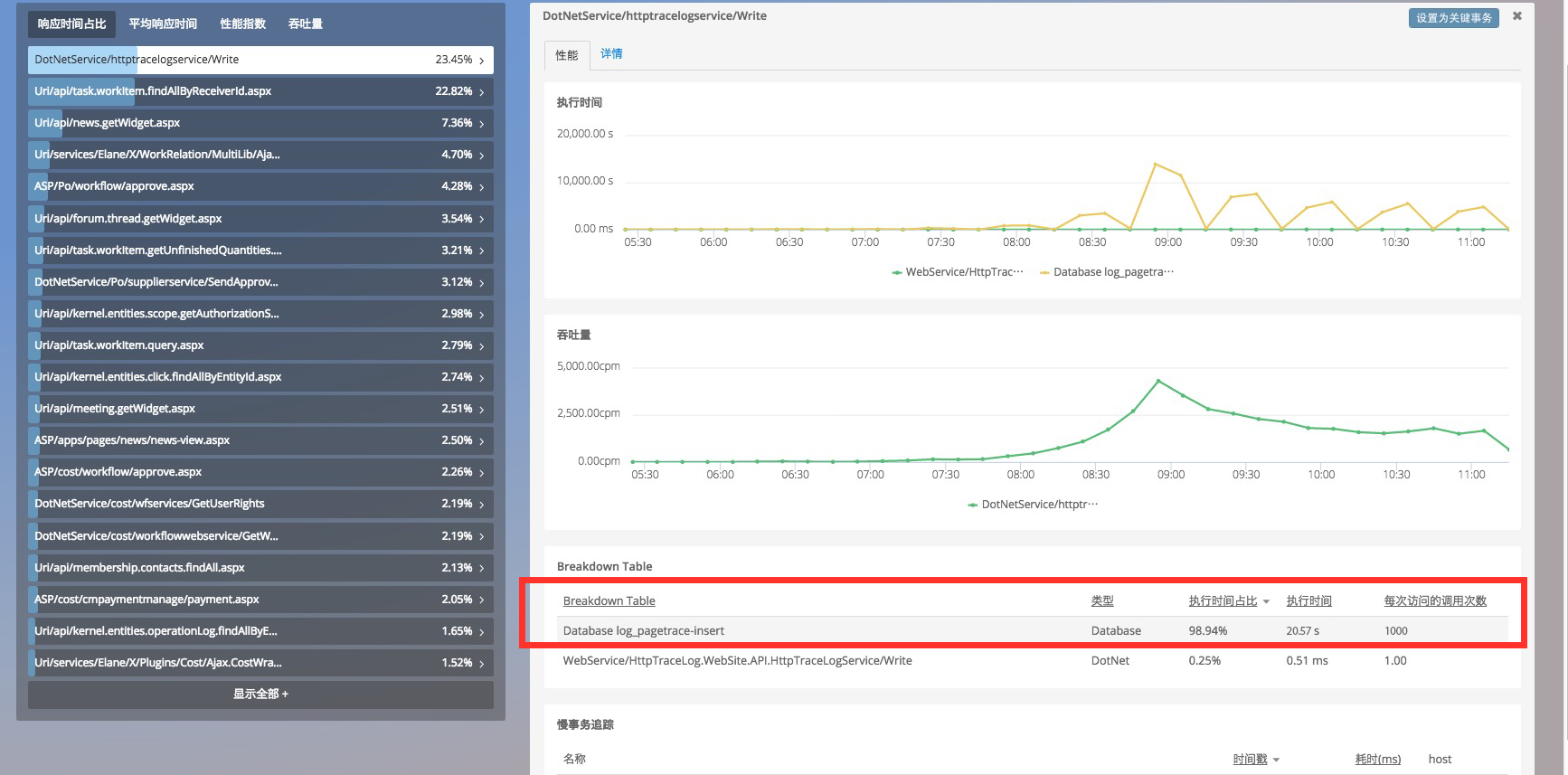
问题调查和分析: 这是一个给 BD 使用的内部应用,这类 Web事务都是在查询和统计当前时间段内该区域所有的外卖订单的相关信息,开发在做这个查询的时候,先查询了所有该区域内的商户对象,然后根据商户一个一个的查询出来他们当前的订单详情,是一个典型的 N+1 问题。
- 针对这个问题可能给出的建议:
对于N+1次查询问题本身来说,使用连接查询就可以轻易地避免这一问题。在这个商户与属性的示例中,可以使用以下连接查询:
>select r., p.
from shanghu_names as r
inner join shanghu_properties as p on p.shanghu_id = r.shanghu_id
结果就是整个执行过程只产生了 1 次查询执行,不再是 1000 多次了!
2、问题类型:一次请求 SQL 大量执行(现象)–低效的连接池访问(原因)–ORM 框架配置(解决方案)
问题发现:同样是在用户现场发现几个 Web 事务有大量的数据库调用,虽然数据库调用数量比较多,但是每次请求的 1000+ 次数据库调用的总执行时间并不是很长(大概 300ms 左右),但是请求总体比较缓慢(平均响应时间在 4s,break down table 中的 database 占比在 10% 上)。
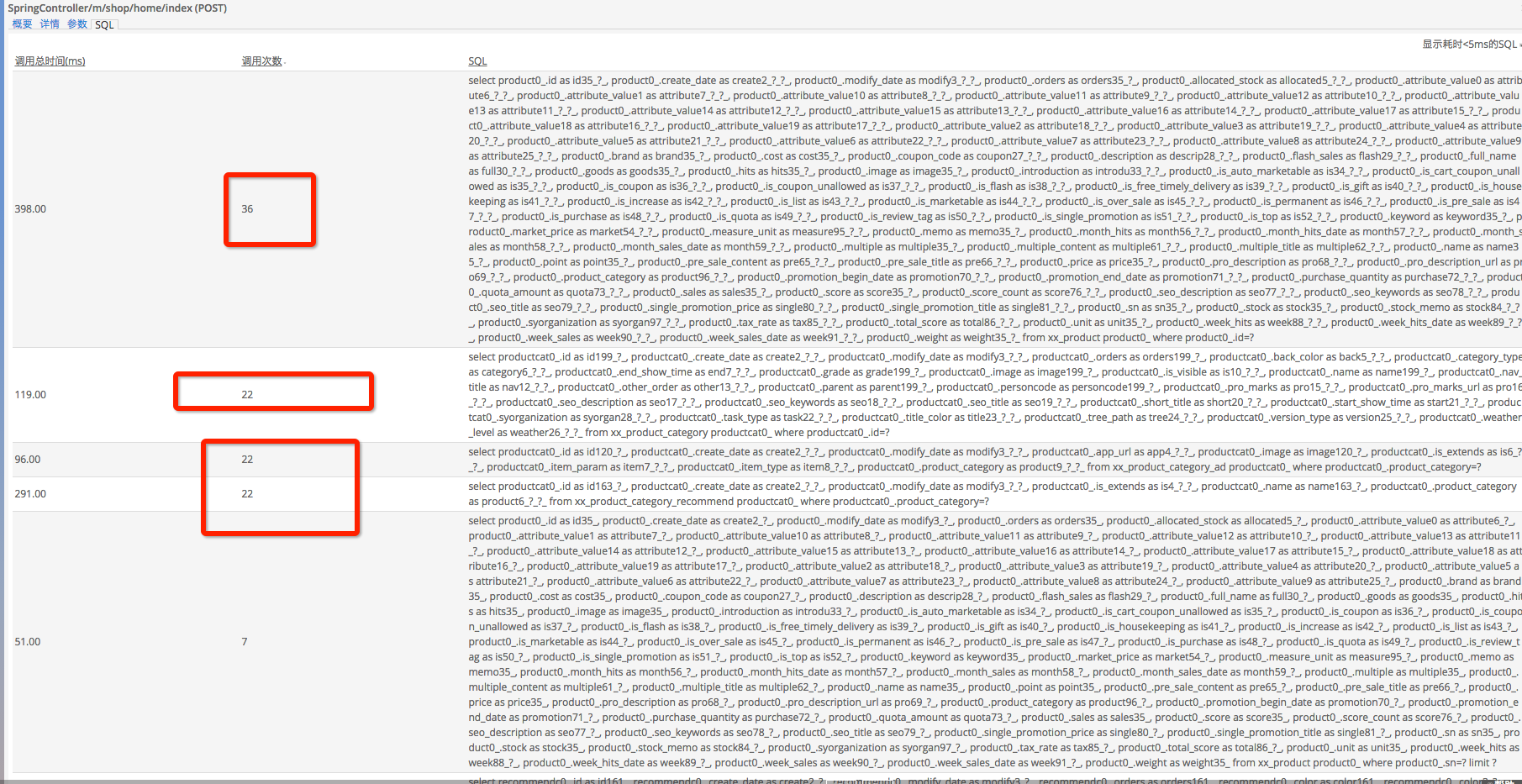 (大量的相同 SQL 被执行)
(大量的相同 SQL 被执行) 问题调查: 这次直接交流的是对应的开发部门,开发部门表示他们使用的 ORM 去调用数据库,业务与上一个案例类似。
问题分析: 经过分析 trace,发现虽然每一次 sql 执行都不慢(5ms左右),但是由于每次SQL查询都要向连接池获取一个新的连接,查询后再释放,导致对于连接词访问次数过多,从而引起访问缓慢。
针对这个问题可能给出的建议: 应用的逻辑需要对某个对象列表进行迭代,但它并没有选择使用“即时加载”(Eager Loading)方式,则是使用了“延迟加载”(Lazy Loading)方式。考虑到我们总是需要获取所有对象,那么更好的方式是“即时加载”(Eager Loading)这些对象,然后考虑对他们进行缓存,前提是这些对象不会变更得十分频繁:(Hibernate 之加载策略(延迟加载与即时加载),来进行这种类型的查询。该用户使用了“延迟加载”(Lazy Loading)方式,它会加载每个对象,并通过独立的 SQL 查询语句获取每个对象的全部属性。每个 SQL 查询都是在一个向连接池获取的JDBC连接中执行的,然后在每个查询完成之后都会返回。查看一下调用 trace 中 getConnection 的出现次数,直接反映出了这个问题。
3、问题类型:连接池资源用尽(原因)
- 问题发现: 某一时间应用整体响应时间飙升,OneAPM 发出报警。
- 问题调查和分析:
- 从web事务角度分析,发现所有缓慢 trace 中的 getconnection 时间的占比较高。
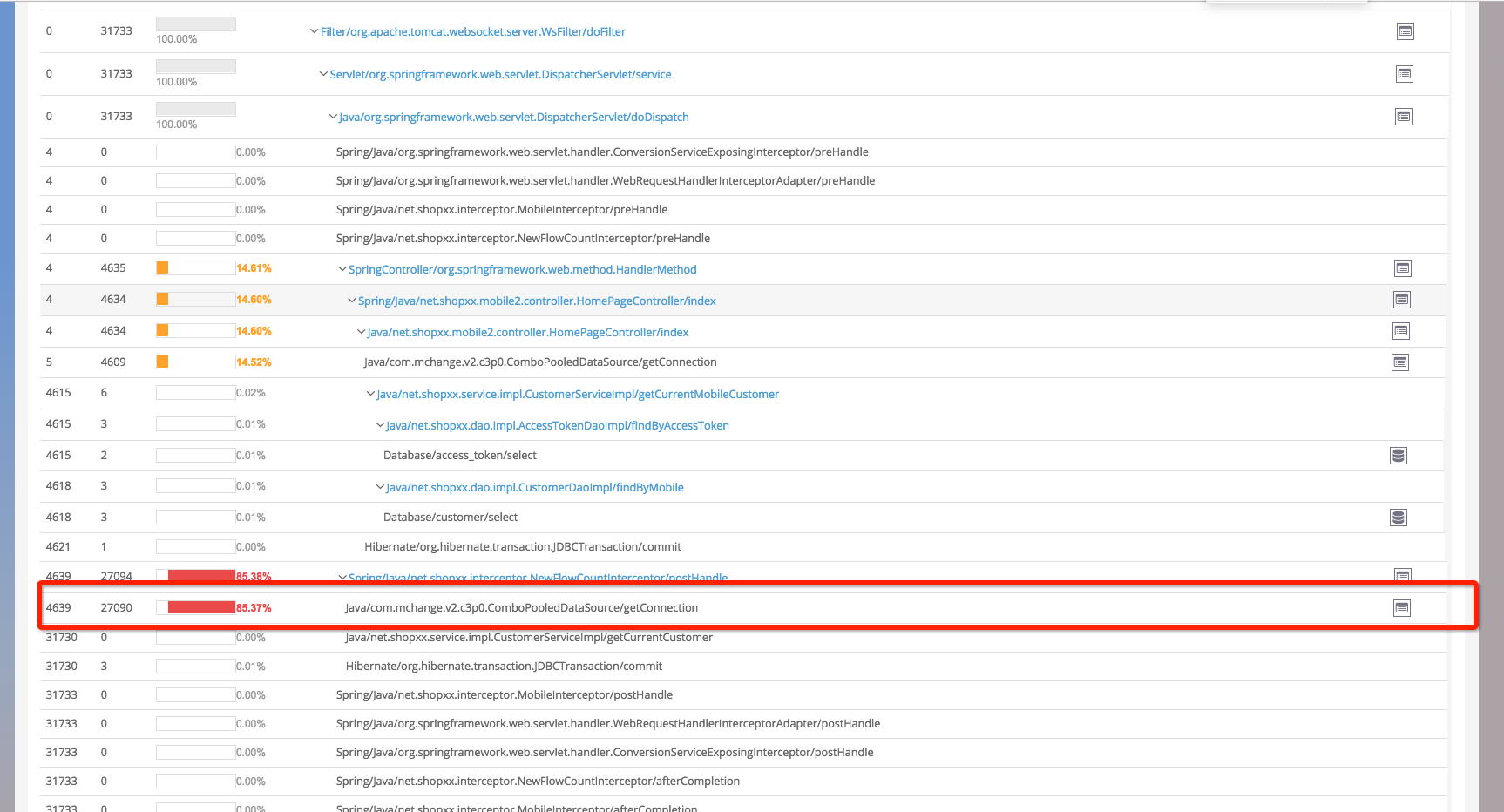
- 从数据库角度分析,发现当时 update 类型操作有一个明显的突起
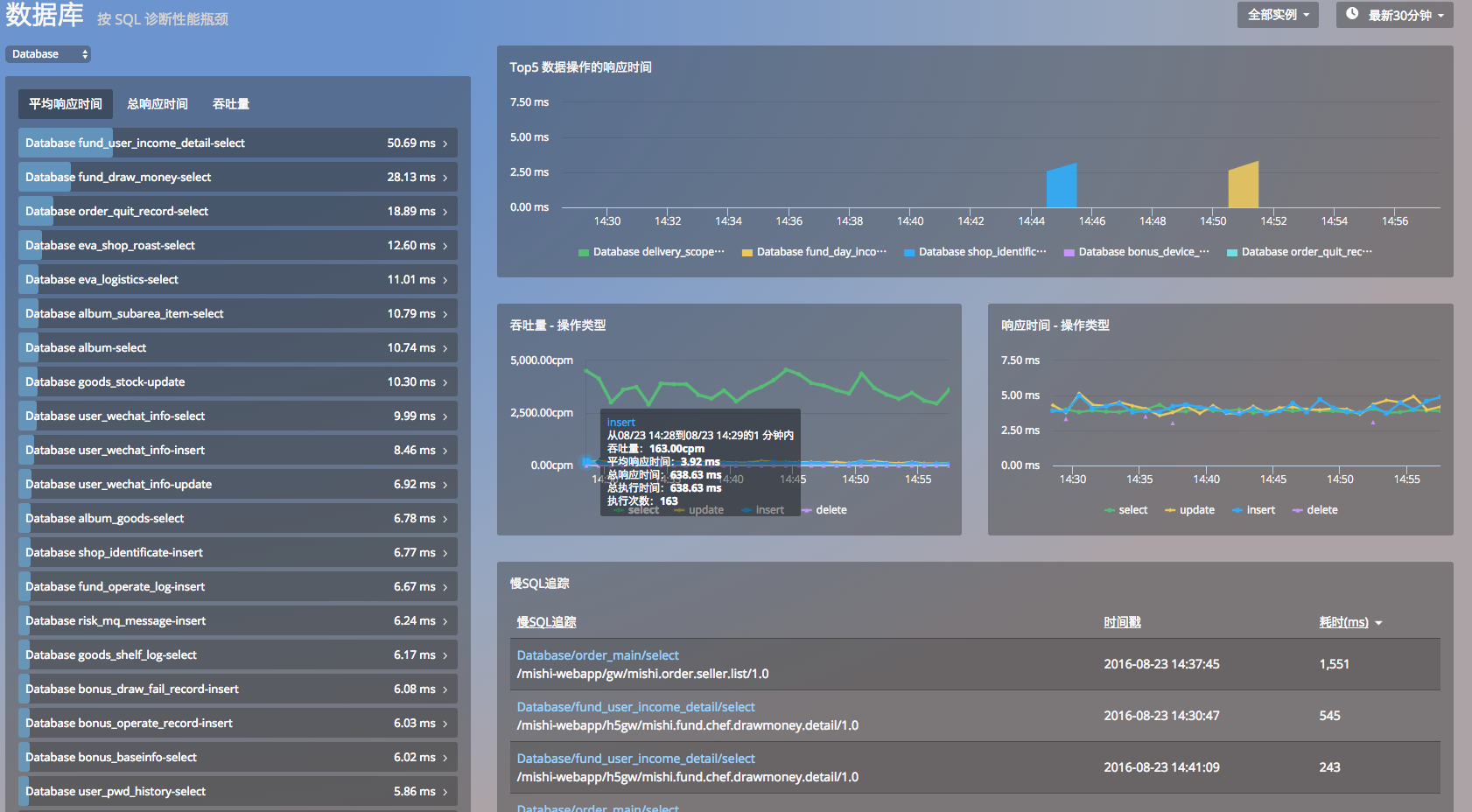
- 查看当时候比较缓慢的 upadate 操作,发现都是由于 当时突然开始运行的 一个后台任务发起的。
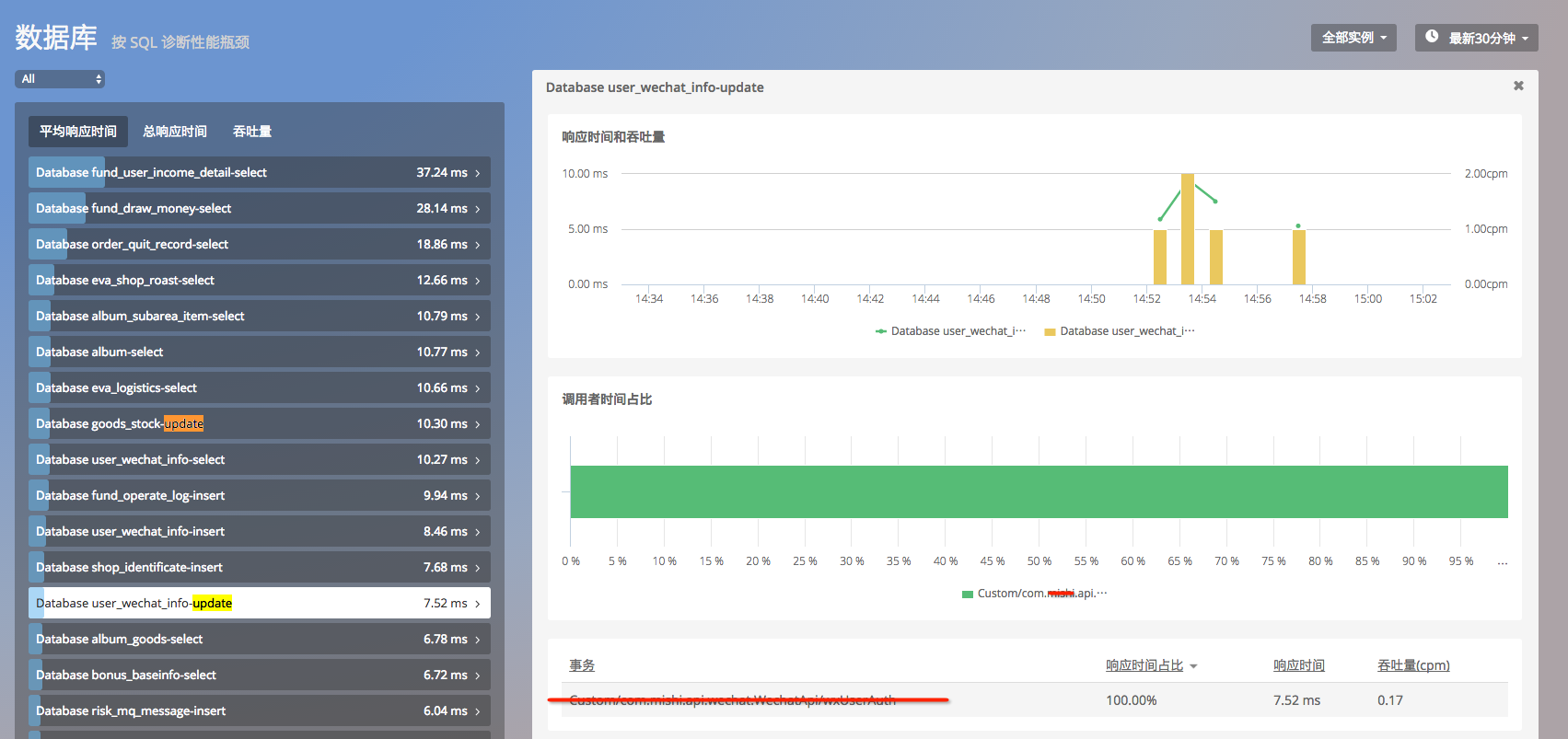
- 最后定位问题: 由于定时的后台任务突然发起的 upadate 操作,导致数据库连接池用尽,导致其他请求无法正常获取数据库连接导致的。
- 从web事务角度分析,发现所有缓慢 trace 中的 getconnection 时间的占比较高。
- 类似的场景:
- 某票务网站的硬件设备会定期请求后台,大约每分钟固定请求 1000 次,正常阶段 select 和 update 操作的 SQL 运行都正常,放票阶段由于大量 update 操作导致数据库锁表,导致用户无法正常打开购票页面。
- 某运营商网站,有一个非常缓慢的报表查询类接口,由于不明原因,短时间内对这个接口有大量访问,导致数据库连接资源用尽,用户其他请求无法得到响应。
- 针对这类问题可能给出的建议:
- 将这些请求发送至独立的服务器上,避免影响其他使用者。
- 重新设定其执行时间,只在不会影响到其他人的时间段才执行,比如凌晨。
- 增加连接池大小,确保在正常的访问量下有足够的连接可用。
4、问题类型:单一 SQL 执行缓慢
- 问题发现:通过分析 Web 事务的 breakdown table,发现请求中最耗时的是对某一个表的 select.
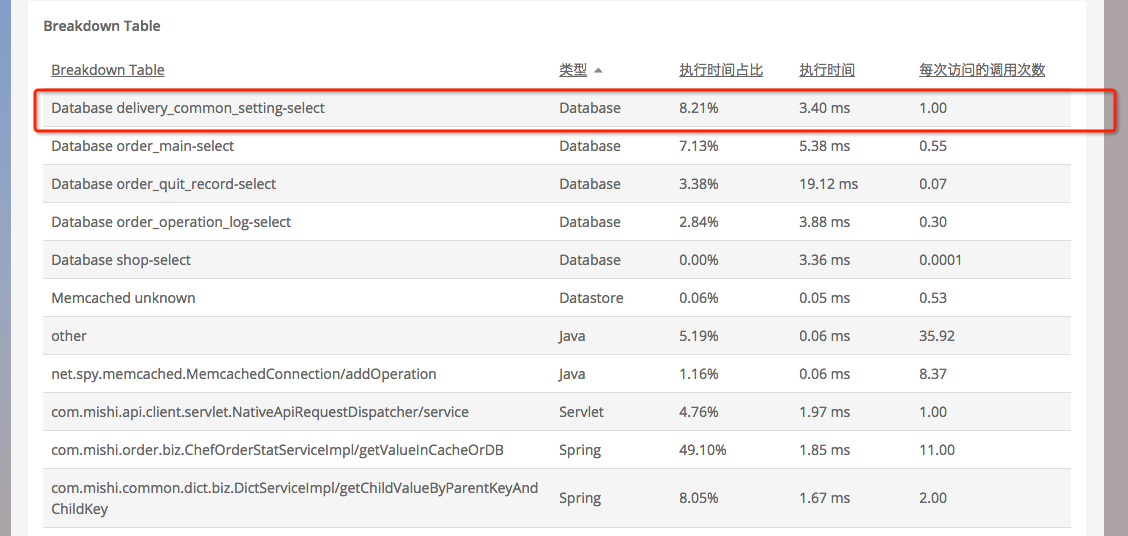
- 针对这类问题可能给出的建议:
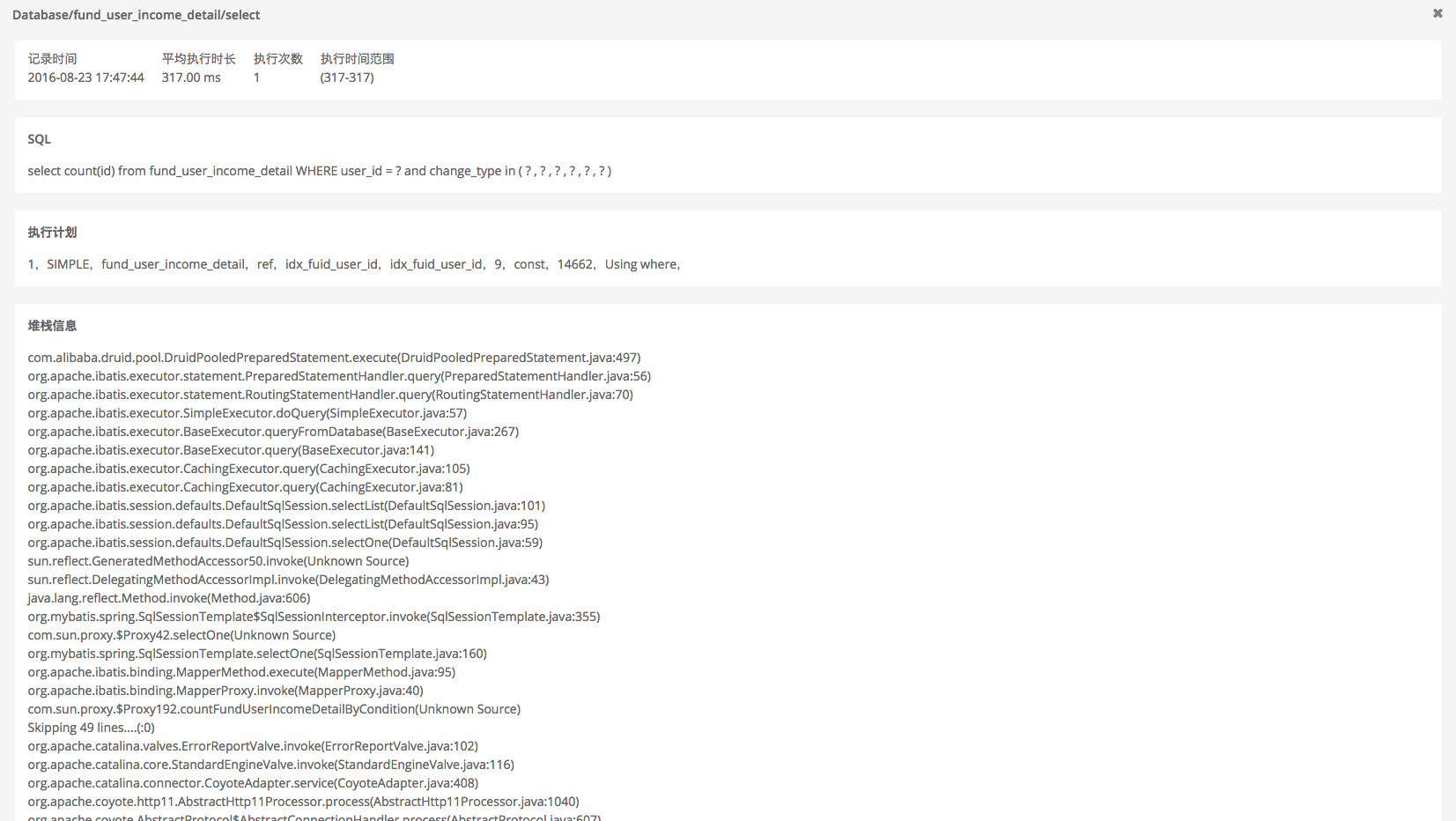 通过分析 SQL 查询执行计划,可以帮组 DBA 优化那些耗时较长的 SQL。
通过分析 SQL 查询执行计划,可以帮组 DBA 优化那些耗时较长的 SQL。