最佳实践之报警
利用报警进行主动式监控
运维专业人员监控 OneAPM 仪表盘,可以很容易看到在各种系统状态诊断信息,但我们并不能保证有人总是盯着仪表盘。除了依靠仪表盘,还可以依靠报警系统,当一个问题需要注意时直接通知操作人员,让您知道什么时候发生的问题。
通过有效利用报警系统,您可以在问题足够严重到您的客户之前找到并解决。例如,不是在系统产生宕机的时候进行报警,而是在系统接近宕机状态时进行提醒。举个例子来说,CPU 的使用率过高或当内存接近其极限。这种类型的警报让您有时间来诊断和解决问题,并防止宕机的发生。
有效的报警可以帮您从纯粹的反应式运维——也就是只有当问题产生客户或者内部投诉时来进行修复支持,变为主动式运维——也就是在问题发生前进行处理。
采用主动监控的做法有很多好处,其中包括:
- 减少支持电话
- 提高客户满意度
- 增加由于响应时间过长等问题而造成的收入
- 延长运维人员的休息时间
采用主动监控的做法时,制定完整的预警是非常重要的。步骤如下所示:
- 确定什么情况应该触发警报
- 集成到报警的工作流程
- 创建,测试报警系统
确定什么情况应该触发报警
一个有效的主动式报警应该集中在关键任务的问题。太少的警报可能会导致重要的问题没有被报到。但是如果人们接收到太多的警告,他们可能会开始忽视告警。一个对企业没有影响的潜在的生产问题不应该被列入到报警的候选对象当中,因为它会产生噪音从而导致我们看不到真正需要关心的报警问题。只对那些需要产生警惕的问题进行报警。
确定什么样的情况发出报警过程涉及相关部门确定其应用的 KPI(关键绩效指标)。基于 KPI 界定生产中的应用什么条件应该触发报警,需要立即引起注意的关键问题,并确定指标,如内存使用。您还可以查看应用程序生命周期中的历史事件,并向所有应用程序所有者咨询他们认为他们的成功的关键。
举个例子来说,假设您有一个“check out”的业务平均响应时间为 1000ms(ART)基于历史信息,您知道如果 ART 超过 3000ms,客户开始放弃他们的购物车当中的商品,如果超过 9000ms,客户开始联系客服或在一些社交媒体上进行抱怨。在这个例子中,如果 ART 超过 3000ms 您可能会想要一些人得到通知,也可能会需要更多的不同的人员群组得到通知。通过通知那些可以利用 OneAPM 进行性能诊断并使 ART 恢复到正常水平的人员,问题的严重性就不会增加到一定程度,进而会影响到您的客户,这样业务营收增长的可能性就会提升。
考虑创建下列条件的警报:
- 一个网站关键业务运行的响应(购买,搜索)太慢。 *可用性低于您的 SLA 阈值。
- 一个关键操作的错误率,如业务交易错误率超过10%。
- 一个数据库或远程服务已停止响应或响应太慢,例如:当一个旅游网站需要从酒店获取定价信息,但是此时信息调用变得非常缓慢,或当一个 LDAP 服务器没有响应。
- JVM 宕机。
您可以发送报警邮件给任何需要解决问题的人或团队。例如,您可能想让警报借道集中报警系统到您的网络运维中心和票务系统。
您也可以使用警报技术来发送您可能会称之为“警告”的特定的人或团队。例如,一个堆内存正在接近它的最大容量时,开发团队可能想知道。这个问题没有严重到来进行一些处理行为,但有信息会给团队一个提醒,告诉他们可能需要在他们的环境中审查的东西。
您也可以创建更多的报警。有关更多信息,见性能指标警报。
集成到报警的工作流程
许多组织已经使用 OneAPM 集成到报警流程,通知相关人员对需要立即关注的问题。例如,假设您当前的警告程序看起来像这样的图表
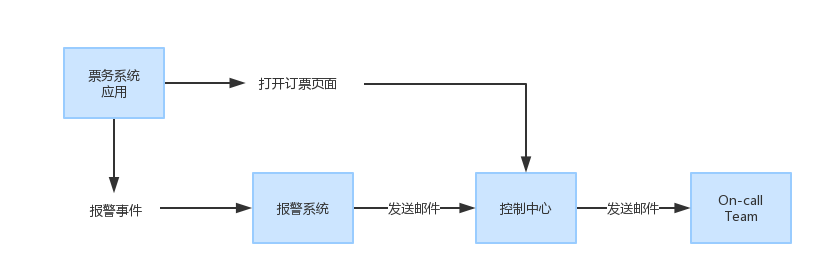
整合后的 OneAPM 提醒到您的工作流程,流程的 OneAPM 流程如下所示:
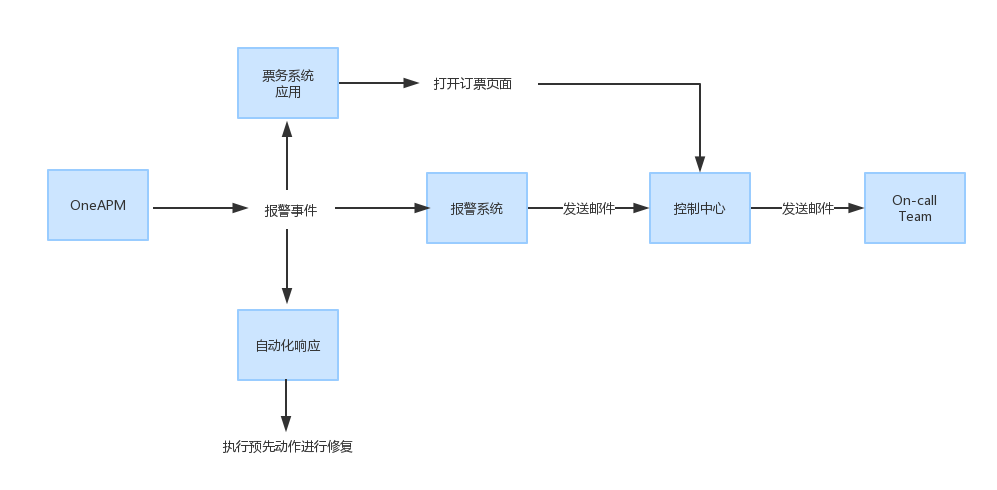
当您确定了什么提醒是必要的,培训团队成员使用 OneAPM 发现并解决问题。
根据警报,一个通知电子邮件可能包含一个节点名称、一个 Tier 名称、一个 Web 事务名称和一个应用程序名称。通知也包含了问题的深度链接以方便用户向下钻取寻找问题的根因。
创建,测试报警系统
在您的团队知道如何响应报警,您就可以开始建立报警。
创建报警,需要进行以下的步骤:
- 定义报警规则阈值。
- 定义报警策略,当数据显示问题正在产生的时候报警触发。
- 配置对应策略触发的行为动作。
用户经常使用“电子邮件”选项作为行动。一个电子邮件通知包含一个事件的详细信息,触发它的深层链接。点击这个链接直接将您直接带到这个地方来解决这个问题。
建议您使用分期的方法,分多次来进行报警的配置。当您第一次使用报警,验证您所发送的最佳类型和数量的警报。创建警报,操作人员将响应,因为他们知道报警反映了一个严重的问题。
这里有一些建议,用于设置和验证临时系统上的报警:
- 对于每一个策略,设置一个发送电子邮件的行为,只有自己或几个核心团队成员。
- 调整警报:
- 如果您收到了很多误报,请调整您的规则条件,触发更少的警报。某些情况下您可能想看包括:设置不同的阈值或基线值,使用不同的评估时间窗口,包括在健康规则多个条件来缩小时将触发警报,警报在一个不同的度量(如“最大”而不是“平均值”)。
- 比较系统的健康信息。如果他们在应该触发报警的时候而没有触发报警,调整您的策略条件,以发送更多的警报。
- 当您确认可从 OneAPM 发送正确的警报,可以尝试除电子邮件以外的其它通知方式。
创建与诊断有关的操作,性能剖析、运行修复脚本等。